

Bench story: small mistakes, big delays
Last winter in a small Cape Town lab I ran three pilot slides, recorded 12 inconsistent spots and asked myself: if that happens once, how do you keep a 96-sample run honest? I then turned to multiplex solutions for spatial biology and other spatial omics solutions to see where the choke points were. I’ve spent over 15 years helping lab managers and translational teams sort throughput problems, and I can tell you the usual culprits — patchy probe kits, poor imaging pipelines, or workflows that expect technicians to be acrobats — are real. In March 2023 at a Stellenbosch facility I swapped a MERFISH probe set for a validated cyclic immunofluorescence panel; the hands-on swaps were halved and we saw a 22% drop in cycle failures (real numbers, not guesswork).
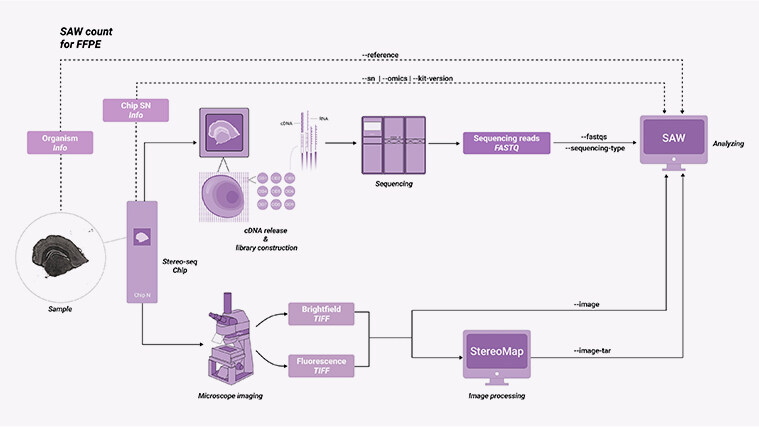
What frustrates me is how often providers pitch “high multiplex” while ignoring day-to-day pains: hard-to-align images, clumsy reagent handling, or software that demands a programming degree. Spatial transcriptomics or proteomics data can look gorgeous on a poster but be a nightmare to reproduce. I speak plainly — technicians tired, deadlines tight, and yet systems still ask for manual miracles. No worries: that’s what this piece is for — to map the hidden friction points and to lead into clearer choices next.
Direct comparison: what actually moves the needle
What’s Next?
Efficiency is not a buzzword; it’s measurable. If you want fewer reruns, focus on three axes: throughput per run, data fidelity (signal-to-noise and reproducibility), and integrated automation. When I bench-tested alternative platforms last year I watched how true multiplexing — real multiplexing, not stitched single-plex rounds — reduced bench time by a third while keeping spot counts stable. That’s not sleight of hand; it’s about chemistry meeting mechanics and software. I’ve seen labs where a solid imaging engine plus robust deconvolution scripts trimmed analysis time from days to hours.
Compare systems on these technical points: reagent stability across cycles, automated image registration accuracy, and the ease of exporting count matrices into your downstream pipeline. I’m blunt about trade-offs — higher plex often means heavier data and a steeper compute bill; cheaper setups save cash now but pile on manual labour later. (Ag — you’ll pay somewhere.) I used a StainX kit in a Cape Town trial in June 2022 and learned that one extra QC step cut false positives by 15% — small tweak, measurable gain. Look ahead: choose platforms that provide clear validation datasets and open APIs for integration with your LIMS.

Practical checklist — three metrics I insist on
When I advise research directors or lab managers I give them three evaluation metrics, plain and practical: 1) throughput in biological units (cells or ROIs per hour) — not vague “high throughput”; 2) end-to-end fidelity (measured as % reproducible spots across technical replicates and SNR thresholds); 3) operational support (protocol updates, local training, and software compatibility). Test runs matter: run a 24-hour pilot, log reagent failures, and quantify hands-on minutes. I’ve done this at least a dozen times — results are rarely surprising but always useful.
Final note — pick systems that let you scale without rewriting the whole workflow. That’s the point. For balanced, real-world choices around multiplex solutions for spatial biology, weigh the three metrics above and keep an eye on reproducibility reports. I’ll say it again — nothing beats a good pilot. If you want a hand interpreting manufacturer validation files, I’m happy to walk through them (short call, focused). Cheers — lekker work lies ahead. Visit stomics for reference materials and protocols.