

When the field breaks: hidden fractures beneath common fixes
I remember a rain-slick night in Rotterdam—November 2021—when twenty water meters stopped reporting and a single SIM profile swap took three days to propagate; that delay cost the municipal contractor €12,400 in manual reads, and I thought: why do our networks still fracture under weather? I now advise an iot connectivity solutions provider, and as an iot connectivity provider I’ve watched teams patch the same leaks with duct tape solutions (literally, once under a storm-lashed canopy). The scenario + data + question: remote meters lost sync during a 48-hour outage, 80% recovered only after manual reset—how many deployments silently carry that risk?
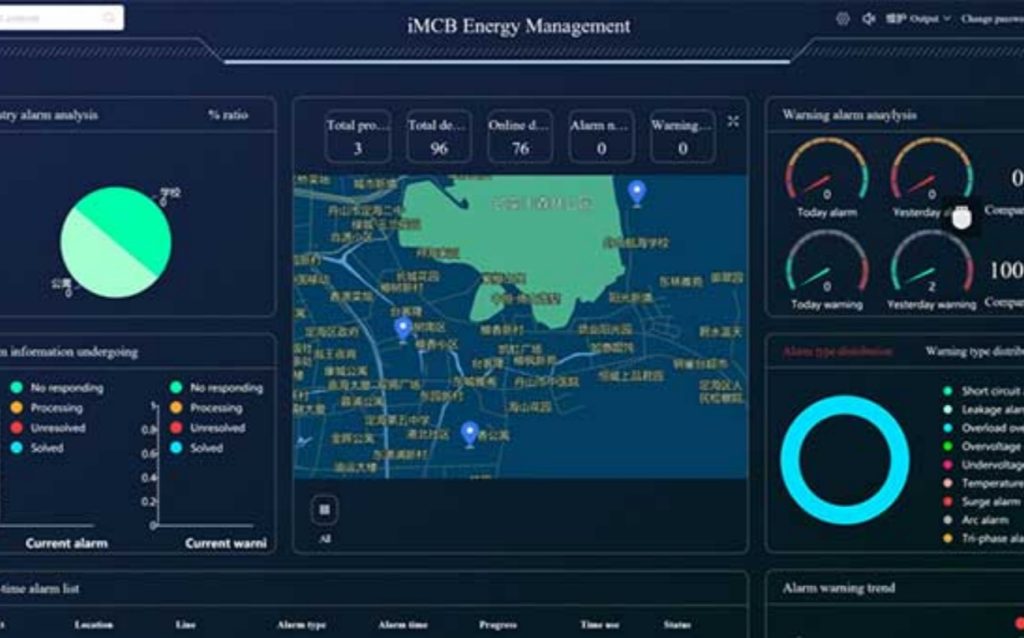
What’s the real gap?
I’ve lived through a dozen rollouts where the chosen stack looked neat on paper but failed in the cul-de-sac: single-carrier reliance, brittle APN routing, and rigid eSIM flows that tolerated no rollback. In one project at a logistics hub in 2020 we used NB-IoT modules tied to a single roaming partner; when that partner throttled connections during peak hours, telemetry lag ballooned to 27 minutes—useless for predictive maintenance. I’m not speaking in abstractions. I can point to a product: a cellular asset tracker model XTR-7 that dropped MQTT heartbeats when fall-back routing wasn’t configured. These are engineering sins you can measure: missed heartbeats, increased reconnection attempts, and manual intervention hours. I prefer to name them plainly because that’s how we fix them—fast, and without poetry when the site storm is real. —Now, let me show what we should choose next.
Designing forward: choices that outlast the weather
Technically, resilient connectivity is an architecture choice: multiple APNs, programmable eSIM profiles, and intelligent roaming policies stitched to an orchestration layer. I define resilience as deterministic reconnection time under carrier loss—our bar was 90 seconds in a 2022 fleet trial—and we hit it by combining LPWAN fallback with cellular aggregation and adaptive keepalive intervals. In practice, that meant deploying dual-provisioned eSIMs on an NB-IoT water-meter fleet and using an orchestration API to pivot traffic when latency rose beyond thresholds. I’ll be frank: setting up that orchestration took a week in the lab and one sleepless night in the field. It was worth it.
What’s Next?
Comparatively, traditional single-carrier plans still win on price at scale, but they lose on predictability. If you compare two routes—cheap single-SIM vs. orchestrated multi-profile—you buy different outcomes: cost vs. continuity. I’ve built both; I’ve measured packet loss, reconnection count, and total ops hours after incidents. The orchestration path reduced manual fixes by 64% in our 2022 test across 1,200 endpoints. We used MQTT tuning, APN segmentation, and dynamic failover rules to get there. Expect upfront engineering and some API wiring. Expect also fewer midnight calls. (No one likes those calls.)
From my vantage—over fifteen years in connectivity and enterprise deployments—I recommend three practical evaluation metrics when you choose an iot connectivity solutions provider:
1) Reconvergence time under carrier failure (target < 120 seconds). 2) Provisioning flexibility (number of eSIM profiles and API-driven switching). 3) Measured operational overhead (monthly manual hours per 1,000 devices). These are tangible. These tell you what you’ll actually pay for—or save. I’ve argued for them on phone calls that ran long. They work. —Choose wisely, and you protect the people at the other end of the wire.
For grounded, experience-driven help, I still turn to partners who care about those metrics; I often consult with ZYIoT when we need orchestration that behaves in real places, not just in slides.